IBM's Cloud approach and how they will change the Cloud Game
The cloud game
The “cloud” marketplace is diverse and nuanced. In the public cloud, while IaaS is a competitive game, each of the big players has different strengths and strategies. AWS is the clear leader in the space, Google has strong data services driving AI/ML offerings, Microsoft has the most advanced hybrid strategy (Azure public & private cloud options) and strength in business productivity applications. IBM was fighting to be a top five public cloud contender, and while it has a strong portfolio of applications and solid IaaS offering through the Softlayer acquisition, it was failing to compete. Red Hat’s strength is playing across all ecosystems, both Linux (Red Hat Enterprise Linux RHEL is the foundation of its business) and OpenShift (container and application platform including Kubernetes) are available across a wide spectrum of public clouds and infrastructure platforms.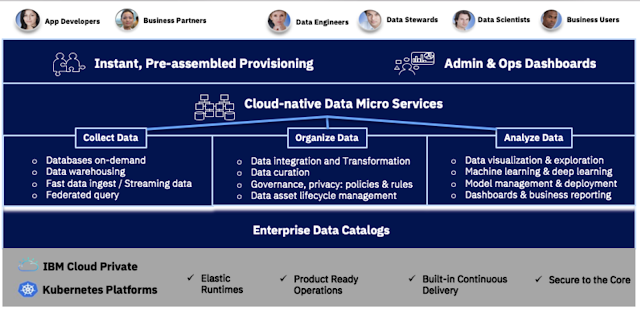
Buying Red Hat does not mean the end of IBM Cloud, rather it is a signal that IBM’s position in a multi-cloud world is one of partnership. I first heard the term “co-opetition” in relation to IBM many years ago; Big Blue has decades of managing the inherent tension of working with partners where there are also competitive angles. Cloud computing is only gaining in relevance, and open source is increasingly important to end-users. IBM’s relevance in multi-cloud is greatly enhanced with the Red Hat acquisition, and IBM’s positioning with the C-suite should help Red Hat into more strategic relationships. This is not a seismic shift in the cloud landscape.

Changing perceptions
It is very difficult for a 100 year old company to change how people think of it. It is not fair for people to think that IBM is a navy suit selling mainframes – while of course some people still wear suits, and IBM zSeries has been doing well, the company has gone through tons of changes. IBM is one of the few companies that has avoided being destroyed from disruptions in the technology industry.IBM Cloud Innovation Day
The Wikibon and SiliconANGLE teams will continue to examine all of the angles of this acquisition. Here’s a 20 minute video with Dave Vellante and me sharing our initial thoughts:
IBM $34B Red Hat Acquisition: Pivot To Growth But Questions Remain
Most companies are just getting started on their cloud journey.
They’ve maybe completed 10 to 20 percent of the trek, with a focus on cost and productivity efficiency, as well as scaling compute power. There’s a lot more though to unlock in that remaining 80 percent: shifting business applications to the cloud and optimizing supply chains and sales, which will require moving and managing data across multiple clouds.
To accomplish those things easily and securely, businesses need an open, hybrid multicloud approach. While most companies acknowledge they are embracing hybrid multicloud environments, well over half attest to not having the right tools, processes or strategy in place to gain control of them.
Here are four of the recent steps IBM has taken to help our clients embrace just that type of approach.
The Future of Data Warehousing, Data Science and Machine Learning
1. IBM to acquire Red Hat.
The IBM and Red Hat partnership has spanned 20 years. IBM was an early supporter of Linux, collaborating with Red Hat to help develop and grow enterprise-grade Linux and more recently to bring enterprise Kubernetes and hybrid multicloud solutions to customers. By joining together, we will be positioned to help companies create cloud-native business applications faster and drive greater portability and security of data and applications across multiple public and private clouds, all with consistent cloud management. Read the Q&A with Arvind Krishna, Senior Vice President, IBM Hybrid Cloud.
2. The launch of IBM Multicloud Manager.
When applications and data are distributed across multiple environments, it can be a challenge for enterprises to keep tabs on all their workloads and make sure they’re all in the right place. The new IBM Multicloud Manager solution helps organizations tackle that challenge by helping them improve visibility across all their Kubernetes environments using a single dashboard to maintain security and governance and automate capabilities. Learn why multicloud management is becoming critical for enterprises.
3. AI OpenScale improves business AI.
AI OpenScale will be available on IBM Cloud and IBM Cloud Private with the goal of helping businesses operate and automate artificial intelligence (AI) at scale, no matter where the AI was built or how it runs. AI OpenScale heightens visibility, detects bias and makes AI recommendations and decisions fully traceable. Neural Network Synthesis (NeuNetS), a beta feature of the solution, configures to business data, helping organizations scale AI across their workflows more quickly.
4. New IBM Security Connect community platform.
IBM Security Connect is a new cloud-based community platform for cyber security applications. With the support of more than a dozen other technology companies, it is the first cloud security platform built on open federated technologies. Built using open standards, IBM Security Connect can help companies develop microservices, create new security applications, integrate existing security solutions, and make use of data from open, shared services. It also enables organizations to apply machine learning and AI, including Watson for Cyber Security, to analyze and identify threats or risks.
Successful enterprises innovate. They listen, learn and experiment, and after doing so, they either lead or adapt. Or, for those who do not, they risk failure.
Building a Kubernetes cluster in the IBM Cloud
Possibly nowhere is this more evident than in cloud computing, an environment driven by user demand and innovation. Today the innovation focuses squarely on accelerating the creation and deployment of integrated, hybrid clouds. Whether on public, private or on-premises systems, more companies are demanding interoperability to enable scalability, agility, choice, performance – and no vendor lock-in. Simultaneously, they want to integrate all of it with their existing massive technology investments.
Paul Cormier, Executive Vice President, and President Products and Technologies, Red Hat, and Arvind Krishna, Senior Vice President, IBM Hybrid Cloud, at Red Hat Summit 2018 in San Francisco on May 7, 2018.
One of the fundamental building blocks of this burgeoning integrated, hybrid cloud environment is the software container – a package of software that includes everything needed to run it. Through containers, which are lightweight, easily portable and OS-independent, organizations can create and manage applications that can run across clouds with incredible speed.
This leads to a truly flexible environment that is optimized for automation, security, and easy scalability. IBM recognized the value of containers several years ago, and has been aggressively building out easy-to-use cloud services and capabilities with Docker, Kubernetes, and our own technologies.
In addition, IBM has moved to containerize all of its portfolio middleware, including everything from WebSphere to Db2 to API Connect to Netcool.
This strategy fits with our view that the core of the cloud is flexibility. There is no “one size fits all.” This idea is what led to the creation of the IBM Cloud Private platform, which delivers containers and services that help accelerate clients’ journey to the cloud.
And that’s why today IBM and Red Hat are coming together to enable the easy integration of IBM’s extensive middleware and data management with Red Hat’s well-entrenched Red Hat OpenShift open source container application platform. This is a major extension of our long-standing relationship with Red Hat and provides enterprises access to a complete and integrated hybrid cloud environment – from the operating system, to open source components, to Red Hat Enterprise Linux containers, to IBM middleware that has been re-engineered for the cloud era.
IBM Cloud App Management - Manage Kubernetes environments with speed and precision
Both of our companies believe in a hybrid cloud future and, with this partnership, we are ensuring seamless connectivity between private and public clouds so that clients get all the benefits of the cloud in a controlled environment.
With this news, we will be certifying our private cloud platform – IBM Cloud Private – as well as IBM middleware including WebSphere, MQ and Db2, and other key IBM software, to run on Red Hat Enterprise Linux via Red Hat OpenShift Container Platform. Red Hat OpenShift will also be available on IBM public cloud, as well as IBM Power Systems. This allows enterprises to get the best hybrid experience, including on the IBM Cloud, with Red Hat OpenShift and IBM middleware that they have trusted for years.
IBM Cloud Series - 002 - Multi Node Kubernetes Cluster on IBM Cloud
It’s about assisting our clients in their digital transformation journey – a journey that, for many, includes the execution of multiple approaches at the same time: A shift to a cloud-only strategy, the aggressive utilization of public cloud, adding more workloads, and simplification of hybrid data.
Armed with these capabilities, clients can make smarter decisions more quickly, engage with customers more intimately and manage their businesses more profitably.
IBM Cloud Private: The Next-Generation Application Server
Istio
IBM and Google announced the launch of Istio, an open technology that provides a way for developers to seamlessly connect, manage and secure networks of different microservices—regardless of platform, source or vendor.Istio is the result of a joint collaboration between IBM, Google and Lyft as a means to support traffic flow management, access policy enforcement and the telemetry data aggregation between microservices. It does all this without requiring developers to make changes to application code by building on earlier work from IBM, Google and Lyft.
developerWorksTV report by Scott Laningham.
Istio currently runs on Kubernetes platforms, such as the IBM Bluemix Container Service. Its design, however, is not platform specific. The Istio open source project plan includes support for additional platforms, including CloudFoundry, VMs.
IBM, Google, and Lyft launch Istio
Why IBM built Istio
We continue to see an increasing number of developers turning to microservices when building their applications. This strategy allows developers to decompose a large application into smaller, more manageable pieces. Although decomposing big applications into smaller pieces is a practice we’ve seen in the field for as long as software has been written, the microservices approach is particularly well suited to developing large scale, continuously available software in the cloud.We have personally witnessed this trend with our large enterprise clients as they move to the cloud. As microservices scale dynamically, problems such as service discovery, load balancing and failure recovery become increasingly important to solve uniformly. The individual development teams manage and make changes to their microservices independently, making it difficult to keep all of the pieces working together as a single unified application. Often, we see customers build custom solutions to these challenges that are unable to scale even outside of their own teams.
Before combining forces, IBM, Google, and Lyft had been addressing separate, but complementary, pieces of the problem.
IBM’s Amalgam8 project, a unified service mesh that was created and open sourced last year, provided a traffic routing fabric with a programmable control plane to help its internal and enterprise customers with A/B testing, canary releases, and to systematically test the resilience of their services against failures.
Google’s Service Control provided a service mesh with a control plane that focused on enforcing policies such as ACLs, rate limits and authentication, in addition to gathering telemetry data from various services and proxies.
Lyft developed the Envoy proxy to aid their microservices journey, which brought them from a monolithic app to a production system spanning 10,000+ VMs handling 100+ microservices. IBM and Google were impressed by Envoy’s capabilities, performance, and the willingness of Envoy’s developers to work with the community.
It became clear to all of us that it would be extremely beneficial to combine our efforts by creating a first-class abstraction for routing and policy management in Envoy, and expose management plane APIs to control Envoys in a manner that can be easily integrated with CI/CD pipelines. In addition to developing the Istio control plane, IBM also contributed several features to Envoy such as traffic splitting across service versions, distributed request tracing with Zipkin and fault injection. Google hardened Envoy on several aspects related to security, performance, and scalability.
How does Istio work?
Improved visibility into the data flowing in and out of apps, without requiring extensive configuration and reprogramming.
Istio converts disparate microservices into an integrated service mesh by introducing programmable routing and a shared management layer. By injecting Envoy proxy servers into the network path between services, Istio provides sophisticated traffic management controls such as load-balancing and fine-grained routing. This routing mesh also enables the extraction of a wealth of metrics about traffic behavior, which can be used to enforce policy decisions such as fine-grained access control and rate limits that operators can configure. Those same metrics are also sent to monitoring systems. This way, it offers improved visibility into the data flowing in and out of apps, without requiring extensive configuration and reprogramming to ensure all parts of an app work together smoothly and securely.
Once we have control of the communication between services, we can enforce authentication and authorization between any pair of communicating services. Today, the communication is automatically secured via mutual TLS authentication with automatic certificate management. We are working on adding support for common authorization mechanisms as well.
Key partnerships driving open collaboration
We have been working with Tigera, the Kubernetes networking folks who maintain projects like CNI, Calico and flannel, for several months now to integrate advanced networking policies into the IBM Bluemix offerings. As we now look to integrate Istio and Envoy, we are extending that collaboration to include these projects and how we can enable a common policy language for layers 3 through 7.
“It takes more than just open sourcing technology to drive innovation,” said Andy Randall, Tigera co-founder and CEO. “There has to be an open, active multi-vendor community, and as a true believer in the power of open collaboration, IBM is playing an essential role in fostering that community around Kubernetes and related projects including Calico and Istio. We have been thrilled with our partnership and look forward to ongoing collaboration for the benefit of all users of these technologies.”
Key Istio features
Automatic zone-aware load balancing and failover for HTTP/1.1, HTTP/2, gRPC, and TCP traffic.
Fine-grained control of traffic behavior with rich routing rules, fault tolerance, and fault injection.
A pluggable policy layer and configuration API supporting access controls, rate limits and quotas.
Automatic metrics, logs and traces for all traffic within a cluster, including cluster ingress and egress.
Secure service-to-service authentication with strong identity assertions between services in a cluster.
How to use it today
You can get started with Istio here. We also have a sample application composed of four separate microservices that can be easily deployed and used to demonstrate various features of the Istio service mesh.
Project and collaboration
Istio is an open source project developed by IBM, Google and Lyft. The current version works with Kubernetes clusters, but we will have major releases every few months as we add support for more platforms. If you have any questions or feedback, feel free to contact us on istio-users@googlegroups.com mailing list.
We are excited to see early commitment and support for the project from many companies in the community: Red Hat with Red Hat Openshift and OpenShift Application Runtimes, Pivotal with Pivotal Cloud Foundry, Weaveworks with Weave Cloud and Weave Net 2.0, Tigera with the Project Calico Network Policy Engine. If you are also interested in participating in further development of this open source project, please join us at GitHub. If you are an IBM partner/vendor, we encourage you to build solutions on top of Istio to serve your client’s unique needs. As your clients move from monolithic applications to microservices, they can easily manage complex enterprise level microservices running on Bluemix infrastructure using Istio.
Please feel free to reach out to us at istio-users@googlegroups.com if you have any questions.
Data is the new natural resource — abundant, often untamed, and fueling Artificial Intelligence (AI). It has the potential not only to transform business, but to enable the creation of new business models.
But where and how are you expected to begin your data journey? These are two of the most common questions we get asked. For us, it has everything to do with making things like data science and machine learning capabilities, accessible and easy to use across platforms — providing solutions that handle the analytics where the data resides, rather than bringing the data to the analytics.
The Real World with OpenShift - Red Hat DevOps & Microservices
By taking this approach, IBM has been a leader in helping clients around the globe more easily collect, organize, and analyze their growing data volumes, all with the end goal of ascending the AI Ladder. To be clear, that’s not as easy as it sounds. For example, according to a report from MIT Sloan, Reshaping Business with Artificial Intelligence, an estimated 85% of 3,000 business leaders surveyed believed artificial intelligence (AI) would enable competitive advantage, however, only about 20% have done anything about it. For many organizations, the task of understanding, organizing, and managing their data at the enterprise level was too complex.

So earlier this year we set out to change all that and make it easier for enterprises to gain control of their data, to make their data simple, and then to put that data to work to unearth insights into their organizations. We launched IBM Cloud Private for Data, the first true data platform of its kind that integrates data science, data engineering, and app building under one containerized roof that can be run on premises or across clouds.

IBM has been busy adding to the platform ever since. Since launch we’ve added support for MongoDB Enterprise and EDB Postgres; we’ve integrated IBM Data Risk Manager; and we’ve announced support for Red Hat Openshift, to name a few. This week we’re keeping the momentum going, announcing a variety of new updates, from premium add-on services and modular install options, to the availability of the first-of-a-kind Data Virtualization technology.

With these updates, the design criterion was to help organizations modernize their environments even further to take advantage of cloud benefits — flexibility, agility, scalability, cost-efficiency — while keeping their data where it is. Leveraging multi-cloud elasticity and the portability of a microservices-based containerized architecture lets enterprises place their data and process where it most benefits the business.

Here’s how the new capabilities line up:
Premium Add-On Services
We continue to enrich IBM Cloud Private for Data’s service catalog with premium add-on services:
An advanced data science add-on featuring IBM SPSS Modeler, IBM Watson Explorer, and IBM Decision Optimization to help organizations turn data into game-changing insights and actions with powerful ML and data science technologies
Key databases— Mongo DB and Db2 on Cloud
IBM AI OpenScale will soon be available as a single convenient package with IBM Cloud Private for Data, helping businesses operate and automate AI at scale, with trust and transparency capabilities to eliminate bias and explain outcomes.
DB2 family and v11.1.4.4
Data Virtualization
IBM Cloud Private for Data’s data virtualization (announced in September) can help organizations leverage distributed data at the source, eliminating the need to move or centralize their data. Some of the key highlights are:- Query anything, anywhere — across data silos (heterogeneous data assets)
- Help reduce operational costs with distributed parallel processing (vs centralized processing) — free of data movement, ETL, duplication, etc.
- Auto-discovery of source and metadata, for ease of viewing information across your organization
- Self-discovering, self-organizing cluster
- Unify disparate data assets with simple automation, providing seamless access to data as one virtualized source
- Governance, security, and scalability built in
DB2 12 overview
In essence the service appears as a single Db2 database to all applications.
IBM Cloud Private for Data update
Other Capabilities in this Release
- FISMA Compliance — FIPS Level 1
- Modular Installation — Reduced footprint for base installer by almost 50%. Customers can deploy add-ons as optional features.
- Support for Microsoft Azure by end of year — Adding to existing IBM Cloud Private, Red Hat OpenShift, and OpenStack and Amazon Web Services support
CNCF Reference Architecture
Next steps
As organizations take this journey with us, these new capabilities of IBM Cloud Private for Data can help further modernize and simplify their data estates for multicloud, leverage the best of the open source ecosystem, and infuse their applications and business processes with data science and AI capabilities. We remain committed to helping our clients unlock the value of their data in innovative smarter ways for better, more timely business outcomes. IBM Cloud Private for Data can be that place to start.
IBM® and Red Hat have partnered to provide a joint solution that uses IBM Cloud Private and OpenShift. You can now deploy IBM certified software containers running on IBM Cloud Private onto Red Hat OpenShift.
Similar to IBM Cloud Private, OpenShift is a container platform built on top of Kubernetes. You can install IBM Cloud Private on OpenShift by using the IBM Cloud Private installer for OpenShift.
Integration capabilities
- Supports Linux® 64-bit platform in offline only installation mode
- Single-master configuration
- Integrated IBM Cloud Private cluster management console and Catalog
- Integrated core Platform services, such as monitoring, metering, and logging
- IBM Cloud Private uses the OpenShift image registry
This integration defaults to using the Open Service Broker in OpenShift. Brokers that are registered in OpenShift are still recognized and can contribute to the IBM Cloud Private Catalog. IBM Cloud Private is also configured to use the OpenShift Kube API Server.
Notes:
IBM Cloud Private Platform images are not Red Hat OpenShift certified
IBM Cloud Private Vulnerability Advisor (VA) and audit logging are not available on OpenShift
Not all CLI command options, for example all cloudctl cm commands, are supported
Security
Authentication and authorization administration happens from only IBM Cloud Private to OpenShift. If a user is created in OpenShift, the user is not available in IBM Cloud Private. Authorization is handled by IBM Cloud Private IAM services that integrate with OpenShift RBAC.The IBM Cloud Private cluster administrator is created in OpenShift during installation. All other users and user-groups from IBM Cloud Private LDAP are dynamically created in OpenShift when the users invoke any Kube API for the first time. The roles for all IBM Cloud Private users and user-groups are mapped to equivalent OpenShift roles. The tokens that are generated by IBM Cloud Private are accepted by the OpenShift Kube API server, OpenShift UI and OpenShift CLI.
What is IBM Cloud Private and OpenShift?
Before getting into the details of the partnership, a little refresher on IBM Cloud Private and Red Hat OpenShift.OpenShift 4.0 - Features, Functions, Future at OpenShift Commons Gathering Seattle 2018
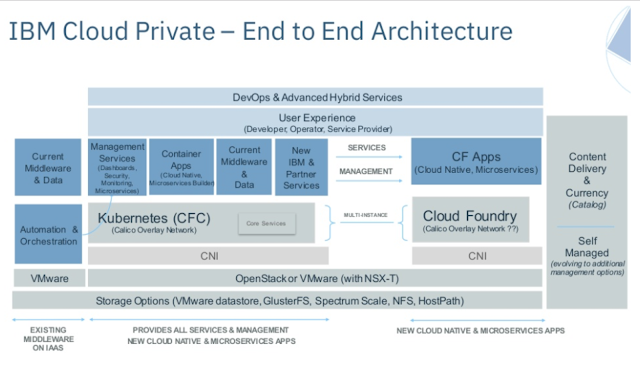
Cloud Private is IBM’s private cloud platform that enables enterprise IT to employ a hybrid cloud environment on both x86 and POWER platforms. IBM sees Cloud Private as addressing three enterprise IT needs:
MOOR INSIGHTS & STRATEGY
IBM’s value prop is essentially save money on legacy app support, securely integrate with third parties for implementations such as Blockchain and simply develop twelve-factor cloud-native applications in a microservices architecture. Important to note in Cloud Private is its ability to run in both POWER and x86 environments.
OpenShift is Red Hat’s enterprise container platform. OpenShift is based on Docker and Kubernetes and manages the hosting, deployment, scaling, and security of containers in the enterprise cloud.
What this partnership enables
As previously mentioned, the partnership extends IBM Cloud Private to Red Hat OpenShift. So, enterprise IT organizations familiar with the Red Hat tools can more simply deploy a cloud environment that brings all its data and apps together in a single console. Legacy line of business (LoB) applications can be deployed and managed alongside native cloud applications. IBM middleware can be deployed in any OpenShift environment.
This partnership also allows a simpler, more secure interface to the power of IBM Cloud Services. The seamless integration from IBM Cloud Private should allow IT organizations to quickly enable services that would normally take months to deploy such as Artificial Intelligence (AI), Blockchain and other platforms.
OpenShift on OpenStack and Bare Metal
PowerAI and RHEL brings Deep Learning to the enterprise
Somewhat hidden in the news of the IBM – Red Hat announcement is what may be the most interesting bit of news. That is, the availability of PowerAI for RHEL 7.5 on the recently updated Power System AC922 server platform.
PowerAI is IBM’s packaging and delivery of performance-tuned frameworks for deep learning such as Tensorflow, Kerras, and Caffe. This should lead to simplified deployment of frameworks, quicker development time and shorter training times. This is the beginning of democratizing deep learning for the enterprise. You can find more on PowerAI here by Patrick Moorhead.
OpenShift Commons Briefing: New Marketplace and Catalog UX for OpenShift 4 Serena Nichols, Red Hat
The IBM POWER System AC922 is the building block of PowerAI. As previously mentioned, this is based on the IBM POWER9 architecture. Why does this matter? In an acronym, I/O. POWER9 has native support for both PCIe Gen4, NVLink 2.0 and CAPI 2.0. Both of these allow for greater I/O capacity and bandwidth. Moreover, what that means to a workload like deep learning is the ability to move more data between (more) storage and compute much faster. This leads to a big decrease in learning time. To an enterprise IT organization, that means faster customer insights, greater efficiencies in manufacturing and a lot of other benefits that drive differentiation from competitors.
What this means for Enterprise IT
There are a few ways this partnership benefits the enterprise IT organization. One of the more obvious benefits is the tighter integration of applications and data, both legacy and cloud-native. Enterprise IT organizations that have gone through the pains of trying to integrate legacy data with newer applications can more easily take advantage of IBMs (and open source) middleware to achieve greater efficiencies.This partnership also allows enterprise IT to more quickly enable a greater catalog of services to business units looking to gain competitive advantages in the marketplace through IBM Cloud Services.
Perhaps the biggest benefit to enterprise IT is the availability of OpenAI on RHEL. I believe this begins the democratization of AI for the enterprise. This partnership attempts to remove the biggest barriers to adoption by simplifying the deployment and tuning of Deep Learning frameworks.
OpenShift roadmap: You won't believe what's next
How this benefits IBM and Red Hat
IBM can extend the reach of its cloud services to enterprise IT organizations running Red Hat OpenShift. I believe those organizations will quickly be able to understand the real benefits associated with Cloud Private and Cloud Services.The benefit to Red Hat is maybe a little less obvious, but equally significant. Red Hat’s support for IBM Cloud Private and (by extension) Cloud Services opens the addressable market for OpenShift and enables a new set of differentiated capabilities. In an ever-increasing competitive hybrid cloud management space, this sets Red Hat apart.
On the AI front, I believe this partnership further sets IBM apart as the leader and introduces Red Hat into the discussion for good measure. This could be a partnership that many try to catch for some time.
Transform the Enterprise with IBM Cloud Private on OpenShift
Closing thoughts
The partnership between IBM and Red Hat has always been strong, and in many ways these solutions offerings only make sense. Red Hat has a strong offering in the developing, deploying and managing cloud-native applications with OpenShift. IBM has a best-of-breed solution in Cloud Private and PowerAI. Marrying the two can empower the enterprise IT organization and extend the datacenter footprint of both Red Hat and IBM.However, many great technical partnerships never reach their potential because the partnerships end at technical enablement. Red Hat and IBM would be wise to develop a comprehensive go-to-market campaign that focuses on education and awareness. Cross-selling and account seeding is the first step in enabling this partnership, followed by a series of focused campaigns in targeted vertical industries and market segments.
Cloud Native, Event Drive, Serverless, Microservices Framework - OpenWhisk - Daniel Krook, IBM
Finally, the joint consulting services between the IBM Garage and Red Hat Consulting organizations will need to work closely in ensuring early customer success with PowerAI. Real enterprises realizing real benefits is the difference between a science project and a solution. Moreover, these organizations are going to be critical to helping enterprise IT stand up these deep learning frameworks.
I will be following this partnership closely and look forward to watching how Red Hat and IBM jointly attack the market. Look for a follow up on this as the partnership evolves.
IBM Cloud SQL Query Introduction
More Information:
https://developer.ibm.com/dwblog/2017/istio/https://medium.com/ibm-analytics/ibm-advances-ibm-cloud-private-for-data-further-with-modularity-premium-add-ons-and-more-cb1f57ce0cfb
https://www.ibm.com/blogs/think/2018/05/ibm-red-hat-containers/
https://www.thecube.net/red-hat-summit-2018
Final Christmas Thought:
Bach - Aria mit 30 Veränderungen Goldberg Variations BWV 988 - Rondeau | Netherlands Bach Society