
Hyperscale Service Tier
Azure SQL Database is based on SQL Server Database Engine architecture that is adjusted for the cloud environment in order to ensure 99.99% availability even in the cases of infrastructure failures. There are three architectural models that are used in Azure SQL Database:- General Purpose/Standard
- Hyperscale
- Business Critical/Premium
Azure SQL Database Hyperscale
For details on the General Purpose and Business Critical service tiers in the vCore-based purchasing model, see General Purpose and Business Critical service tiers. For a comparison of the vCore-based purchasing model with the DTU-based purchasing model, see Azure SQL Database purchasing models and resources.
The Hyperscale service tier is currently only available for Azure SQL Database, and not Azure SQL Managed Instance.
Hyperscale
What are the Hyperscale capabilities
The Hyperscale service tier in Azure SQL Database provides the following additional capabilities:- Support for up to 100 TB of database size
- Nearly instantaneous database backups (based on file snapshots stored in Azure Blob storage) regardless of size with no IO impact on compute resources
- Fast database restores (based on file snapshots) in minutes rather than hours or days (not a size of data operation)
- Higher overall performance due to higher log throughput and faster transaction commit times regardless of data volumes
- Rapid scale out - you can provision one or more read-only nodes for offloading your read workload and for use as hot-standbys
- Rapid Scale up - you can, in constant time, scale up your compute resources to accommodate heavy workloads when needed, and then scale the compute resources back down when not needed.
What is Azure SQL Database Hyperscale?
Creating Powerful SAP Environments on Hyper-Scale Cloud
Additionally, the time required to create database backups or to scale up or down is no longer tied to the volume of data in the database. Hyperscale databases can be backed up virtually instantaneously. You can also scale a database in the tens of terabytes up or down in minutes. This capability frees you from concerns about being boxed in by your initial configuration choices.
For more information about the compute sizes for the Hyperscale service tier, see Service tier characteristics.
Who should consider the Hyperscale service tier
The Hyperscale service tier is intended for most business workloads as it provides great flexibility and high performance with independently scalable compute and storage resources. With the ability to autoscale storage up to 100 TB, it's a great choice for customers who:Have large databases on-premises and want to modernize their applications by moving to the cloud
Are already in the cloud and are limited by the maximum database size restrictions of other service tiers (1-4 TB)
Have smaller databases, but require fast vertical and horizontal compute scaling, high performance, instant backup, and fast database restore.
The Hyperscale service tier supports a broad range of SQL Server workloads, from pure OLTP to pure analytics, but it's primarily optimized for OLTP and hybrid transaction and analytical processing (HTAP) workloads.
Important
Elastic pools do not support the Hyperscale service tier.
Hyperscale pricing model
Hyperscale service tier is only available in vCore model. To align with the new architecture, the pricing model is slightly different from General Purpose or Business Critical service tiers:Compute:
The Hyperscale compute unit price is per replica. The Azure Hybrid Benefit price is applied to read scale replicas automatically. We create a primary replica and one read-only replica per Hyperscale database by default. Users may adjust the total number of replicas including the primary from 1-5.
Storage:
You don't need to specify the max data size when configuring a Hyperscale database. In the hyperscale tier, you're charged for storage for your database based on actual allocation. Storage is automatically allocated between 40 GB and 100 TB, in 10-GB increments. Multiple data files can grow at the same time if needed. A Hyperscale database is created with a starting size of 10 GB and it starts growing by 10 GB every 10 minutes, until it reaches the size of 40 GB.
For more information about Hyperscale pricing, see Azure SQL Database Pricing
DataOps for the Modern Data Warehouse on Microsoft Azure @ NDCOslo 2020 - Lace Lofranco
DataOps for the Modern Data Warehouse on Microsoft Azure @ NDCOslo 2020 - Lace Lofranco from Lace Lofranco
Distributed functions architecture
Unlike traditional database engines that have centralized all of the data management functions in one location/process (even so called distributed databases in production today have multiple copies of a monolithic data engine), a Hyperscale database separates the query processing engine, where the semantics of various data engines diverge, from the components that provide long-term storage and durability for the data. In this way, the storage capacity can be smoothly scaled out as far as needed (initial target is 100 TB). Read-only replicas share the same storage components so no data copy is required to spin up a new readable replica.
The following diagram illustrates the different types of nodes in a Hyperscale database:

A Hyperscale database contains the following different types of components:
Compute
The compute node is where the relational engine lives, so all the language elements, query processing, and so on, occur. All user interactions with a Hyperscale database happen through these compute nodes. Compute nodes have SSD-based caches (labeled RBPEX - Resilient Buffer Pool Extension in the preceding diagram) to minimize the number of network round trips required to fetch a page of data. There is one primary compute node where all the read-write workloads and transactions are processed. There are one or more secondary compute nodes that act as hot standby nodes for failover purposes, as well as act as read-only compute nodes for offloading read workloads (if this functionality is desired).Page server
Page servers are systems representing a scaled-out storage engine. Each page server is responsible for a subset of the pages in the database. Nominally, each page server controls between 128 GB and 1 TB of data. No data is shared on more than one page server (outside of replicas that are kept for redundancy and availability). The job of a page server is to serve database pages out to the compute nodes on demand, and to keep the pages updated as transactions update data. Page servers are kept up to date by playing log records from the log service. Page servers also maintain SSD-based caches to enhance performance. Long-term storage of data pages is kept in Azure Storage for additional reliability.
Building Advanced Analytics Pipelines with Azure Databricks
Log service
The log service accepts log records from the primary compute replica, persists them in a durable cache, and forwards the log records to the rest of compute replicas (so they can update their caches) as well as the relevant page server(s), so that the data can be updated there. In this way, all data changes from the primary compute replica are propagated through the log service to all the secondary compute replicas and page servers. Finally, the log records are pushed out to long-term storage in Azure Storage, which is a virtually infinite storage repository. This mechanism removes the need for frequent log truncation. The log service also has local cache to speed up access to log records.Azure storage
Azure Storage contains all data files in a database. Page servers keep data files in Azure Storage up to date. This storage is used for backup purposes, as well as for replication between Azure regions. Backups are implemented using storage snapshots of data files. Restore operations using snapshots are fast regardless of data size. Data can be restored to any point in time within the backup retention period of the database.
Amsterdam Modern Data Warehouse OpenHack - DataDevOps
Backup and restore
Backups are file-snapshot based and hence they're nearly instantaneous. Storage and compute separation enables pushing down the backup/restore operation to the storage layer to reduce the processing burden on the primary compute replica. As a result, database backup doesn't impact performance of the primary compute node. Similarly, restores are done by reverting to file snapshots, and as such aren't a size of data operation. Restore is a constant-time operation, and even multiple-terabyte databases can be restored in minutes instead of hours or days. Creation of new databases by restoring an existing backup also takes advantage of this feature: creating database copies for development or testing purposes, even of terabyte sized databases, is doable in minutes.Mark Russinovich on Azure SQL Database Edge, Hyperscale, and beyond | Data Exposed
Scale and performance advantages
With the ability to rapidly spin up/down additional read-only compute nodes, the Hyperscale architecture allows significant read scale capabilities and can also free up the primary compute node for serving more write requests. Also, the compute nodes can be scaled up/down rapidly due to the shared-storage architecture of the Hyperscale architecture.Create a Hyperscale database
A Hyperscale database can be created using the Azure portal, T-SQL, PowerShell, or CLI. Hyperscale databases are available only using the vCore-based purchasing model.The following T-SQL command creates a Hyperscale database. You must specify both the edition and service objective in the CREATE DATABASE statement. Refer to the resource limits for a list of valid service objectives.
SQL
-- Create a Hyperscale Database
CREATE DATABASE [HyperscaleDB1] (EDITION = 'Hyperscale', SERVICE_OBJECTIVE = 'HS_Gen5_4');
GO
This will create a Hyperscale database on Gen5 hardware with four cores.
Upgrade existing database to Hyperscale
You can move your existing databases in Azure SQL Database to Hyperscale using the Azure portal, T-SQL, PowerShell, or CLI. At this time, this is a one-way migration. You can't move databases from Hyperscale to another service tier, other than by exporting and importing data. For proofs of concept (POCs), we recommend making a copy of your production databases, and migrating the copy to Hyperscale. Migrating an existing database in Azure SQL Database to the Hyperscale tier is a size of data operation.
The following T-SQL command moves a database into the Hyperscale service tier. You must specify both the edition and service objective in the ALTER DATABASE statement.
SQL
-- Alter a database to make it a Hyperscale Database
ALTER DATABASE [DB2] MODIFY (EDITION = 'Hyperscale', SERVICE_OBJECTIVE = 'HS_Gen5_4');
GO
Connect to a read-scale replica of a Hyperscale database
In Hyperscale databases, the ApplicationIntent argument in the connection string provided by the client dictates whether the connection is routed to the write replica or to a read-only secondary replica. If the ApplicationIntent set to READONLY and the database doesn't have a secondary replica, connection will be routed to the primary replica and defaults to ReadWrite behavior.
cmd
-- Connection string with application intent
Server=tcp:.database.windows.net;Database= ;ApplicationIntent=ReadOnly;User ID= ;Password= ;Trusted_Connection=False; Encrypt=True;
Hyperscale secondary replicas are all identical, using the same Service Level Objective as the primary replica. If more than one secondary replica is present, the workload is distributed across all available secondaries. Each secondary replica is updated independently. Thus, different replicas could have different data latency relative to the primary replica.
Database high availability in Hyperscale
As in all other service tiers, Hyperscale guarantees data durability for committed transactions regardless of compute replica availability. The extent of downtime due to the primary replica becoming unavailable depends on the type of failover (planned vs. unplanned), and on the presence of at least one secondary replica. In a planned failover (i.e. a maintenance event), the system either creates the new primary replica before initiating a failover, or uses an existing secondary replica as the failover target. In an unplanned failover (i.e. a hardware failure on the primary replica), the system uses a secondary replica as a failover target if one exists, or creates a new primary replica from the pool of available compute capacity. In the latter case, downtime duration is longer due to extra steps required to create the new primary replica.For Hyperscale SLA, see SLA for Azure SQL Database.
Disaster recovery for Hyperscale databases
Restoring a Hyperscale database to a different geographyIf you need to restore a Hyperscale database in Azure SQL Database to a region other than the one it's currently hosted in, as part of a disaster recovery operation or drill, relocation, or any other reason, the primary method is to do a geo-restore of the database. This involves exactly the same steps as what you would use to restore any other database in SQL Database to a different region:
Create a server in the target region if you don't already have an appropriate server there. This server should be owned by the same subscription as the original (source) server.
Follow the instructions in the geo-restore topic of the page on restoring a database in Azure SQL Database from automatic backups.
Because the source and target are in separate regions, the database cannot share snapshot storage with the source database as in non-geo restores, which complete extremely quickly. In the case of a geo-restore of a Hyperscale database, it will be a size-of-data operation, even if the target is in the paired region of the geo-replicated storage. That means that doing a geo-restore will take time proportional to the size of the database being restored. If the target is in the paired region, the copy will be within a region, which will be significantly faster than a cross-region copy, but it will still be a size-of-data operation.
Get high-performance scaling for your Azure database workloads with Hyperscale
In today’s data-driven world, driving digital transformation increasingly depends on our ability to manage massive amounts of data and harness its potential. Developers who are building intelligent and immersive applications should not have to be constrained by resource limitations that ultimately impact their customers’ experience.
Unfortunately, resource limits are an inescapable reality for application developers. Almost every developer can recall a time of when database compute, storage and memory limitations impacted an application’s performance. The consequences are real; from the time and cost spent compensating for platform limitations, to higher latency of usability, and even downtime associated with large data operations.
Microsoft Ignite AU 2017 - Orchestrating Big Data Pipelines with Azure Data Factory
Microsoft Ignite AU 2017 - Orchestrating Big Data Pipelines with Azure Data Factory from Lace Lofranco
We have already broken limits on NoSQL with Azure Cosmos DB, a globally distributed multi-model database with multi-master replication. We have also delivered blazing performance at incredible value with Azure SQL Data Warehouse. Today, we are excited to deliver a high-performance scaling capability for applications using the relational model, Hyperscale, which further removes limits for application developers.
Azure SQL Database: Serverless & Hyperscale
Hyperscale Explained
Hyperscale is a new cloud-native solution purpose-built to address common cloud scalability limits with either compute, storage, memory or combinations of all three. Best of all, you can harness Hyperscale without rearchitecting your application. The technology implementation of Hyperscale is optimized for different scenarios and customized by database engine.Announcing:
- Azure Database for PostgreSQL Hyperscale (available in preview)
- Azure SQL Database Hyperscale (generally available)
- Azure Database for PostgreSQL Hyperscale
Hyperscale (powered by Citus Data technology) brings high-performance scaling to PostgreSQL database workloads by horizontally scaling a single database across hundreds of nodes to deliver blazingly fast performance and scale. This allows more data to fit in-memory, parallelize queries across hundreds of nodes, and index data faster. This enables developers to satisfy workload scenarios that require ingesting and querying data in real-time, with sub-second response times, at any scale – even with billions of rows. The addition of Hyperscale as a deployment option for Azure Database for PostgreSQL simplifies infrastructure and application design, saving time to focus on business needs. Hyperscale is compatible with the latest innovations, versions and tools of PostgreSQL, so you can leverage your existing PostgreSQL expertise.
Also, the Citus extension is available as an open source download on GitHub. We are committed to partnering with the PostgreSQL community on staying current with the latest releases so developers can stay productive.
Use Azure Database for PostgreSQL Hyperscale for low latency, high-throughput scenarios like:
- Developing real-time operational analytics
- Enabling multi-tenant SaaS applications
- Building transactional applications
Learn more about Hyperscale on Azure Database for PostgreSQL.
Unleash analytics on operational data with Hyperscale (Citus) on Azure Database for PostgreSQL
Azure SQL Database Hyperscale
Azure SQL Database Hyperscale is powered by a highly scalable storage architecture that enables a database to grow as needed, effectively eliminating the need to pre-provision storage resources. Scale compute and storage resources independently, providing flexibility to optimize performance for workloads. The time required to restore a database or to scale up or down is no longer tied to the volume of data in the database and database backups are virtually instantaneous. With read-intensive workloads, Hyperscale provides rapid scale-out by provisioning additional read replicas as needed for offloading read workloads.Azure SQL Database Hyperscale joins the General Purpose and Business Critical service tiers, which are configured to serve a spectrum of workloads.
General Purpose - offers balanced compute and storage, and is ideal for most business workloads with up to 8 TB of storage.
Business Critical - optimized for data applications with fast IO and high availability requirements with up to 4 TB of storage.
Azure SQL Database Hyperscale is optimized for OLTP and high throughput analytics workloads with storage up to 100TB. Satisfy highly scalable storage and read-scale requirements and migrate large on-premises workloads and data marts running on symmetric multiprocessor (SMP) databases. Azure SQL Database Hyperscale significantly expands the potential for application growth without being limited by storage size.
Learn more about Azure SQL Database Hyperscale.
Azure SQL Database Hyperscale is not the only SQL innovation we are announcing today! Azure SQL Database is also introducing a new serverless compute option: Azure SQL Database serverless. This new option allows compute and memory to scale independently based on the workload requirements. Compute is automatically paused and resumed, eliminating the requirements of managing capacity and reducing cost. Azure SQL Database serverless is a fantastic option for applications with unpredictable or intermittent compute requirements.Hyperscale hardware: ML at scale on top of Azure + FPGA : Build 2018
Learn more about Azure SQL Database serverless.
Build applications in a familiar environment with tools you knowAzure relational databases share more than Hyperscale. They are built upon the same platform, with innovations like intelligence and security shared across the databases so you can be most productive in the engine of your choice.
Trained on millions of databases over the years, these intelligent features:
- Inspect databases to understand the workloads
- Identify bottlenecks
Automatically recommend options to optimize application performance
Intelligence also extends to security features like:
- Advanced threat protection that continuously monitors for suspicious activities
- Providing immediate security alerts on potential vulnerabilities
- Recommending actions on how to investigate and mitigate threats
Because we do not rely upon forked versions of our engines, you can confidently develop in a familiar environment with the tools you are used to – and rest assured that your hyperscaled database is always compatible and in-sync with the latest SQL and PostgreSQL versions.
Best better Hyperscale: The last database you will ever need in the cloud | BRK3028
Bring Azure data services to your infrastructure with Azure Arc
With the exponential growth in data, organizations find themselves in increasingly heterogenous data estates, full of data sprawl and silos, spreading across on-premises data centers, the edge, and multiple public clouds. It has been a balancing act for organizations trying to bring about innovation faster while maintaining consistent security and governance. The lack of a unified view of all their data assets across their environments poses extra complexity for best practices in data management.As Satya announced in his vision keynote at Microsoft Ignite, we are redefining hybrid by bringing innovation anywhere with Azure. We are introducing Azure Arc, which brings Azure services and management to any infrastructure. This enables Azure data services to run on any infrastructure using Kubernetes. Azure SQL Database and Azure Database for PostgreSQL Hyperscale are both available in preview on Azure Arc, and we will bring more data services to Azure Arc over time.
For customers who need to maintain data workloads in on-premises datacenters due to regulations, data sovereignty, latency, and so on, Azure Arc can bring the latest Azure innovation, cloud benefits like elastic scale and automation, unified management, and unmatched security on-premises.
Designing Networking and Hybrid Connectivity in Azure
Always current
A top pain point we continue to hear from customers is the amount of work involved in patching and updating their on-premises databases. It requires constant diligence from corporate IT to ensure all databases are updated in a timely fashion. A fully managed database service, such as Azure SQL Database, removes the burden of patching and upgrades for customers who have migrated their databases to Azure.
Azure Arc helps to fully automate the patching and update process for databases running on-premises. Updates from the Microsoft Container Registry are automatically delivered to customers, and deployment cadences are set by customers in accordance with their policies. This way, on-premises databases can stay up to date while ensuring customers maintain control.
Azure Arc also enables on-premises customers to access the latest innovations such as the evergreen SQL through Azure SQL Database, which means customers will no longer face end-of-support for their databases. Moreover, a unique hyper-scale deployment option of Azure Database for PostgreSQL is made available on Azure Arc. This capability gives on-premises data workloads an additional boost on capacity optimization, using unique scale-out across reads and writes without application downtime.
Big Data from Microsoft Azure Robert Turnage Data Solutions Architect
Elastic scale
Cloud elasticity on-premises is another unique capability Azure Arc offers customers. The capability enables customers to scale their databases up or down dynamically in the same way as they do in Azure, based on the available capacity of their infrastructure. This can satisfy burst scenarios that have volatile needs, including scenarios that require ingesting and querying data in real-time, at any scale, with sub-second response time. In addition, customers can also scale-out database instances by setting up read replicas across multiple data centers or from their own data center into any public cloud.
Azure Arc also brings other cloud benefits such as fast deployment and automation at scale. Thanks to Kubernetes-based execution, customers can deploy a database in seconds, setting up high availability, backup, point-in-time-restore with a few clicks. Compare this to the time and resource-consuming manual work that is currently required to do the same on-premises, these new capabilities will greatly improve productivity of database administration and enable faster continuous integration and continuous delivery, so the IT team can be more agile to unlock business innovation.
Scalable Data Science with SparkR on HDInsight
Unified management
Using familiar tools such as the Azure portal, Azure Data Studio, and the Azure CLI, customers can now gain a unified view of all their data assets deployed with Azure Arc. Customers are able to not only view and manage a variety of relational databases across their environment and Azure, but also get logs and telemetry from Kubernetes APIs to analyze the underlying infrastructure capacity and health. Besides having localized log analytics and performance monitoring, customers can now leverage Azure Monitor on-premises for comprehensive operational insights across their entire estate. Moreover, Azure Backup can be easily connected to provide long-term, off-site backup retention and disaster recovery. Best of all, customers can now use cloud billing models for their on-premises data workloads to manage their costs efficiently.
See a full suite of management capabilities provided by Azure Arc (Azure Arc data controller) from the below diagram.
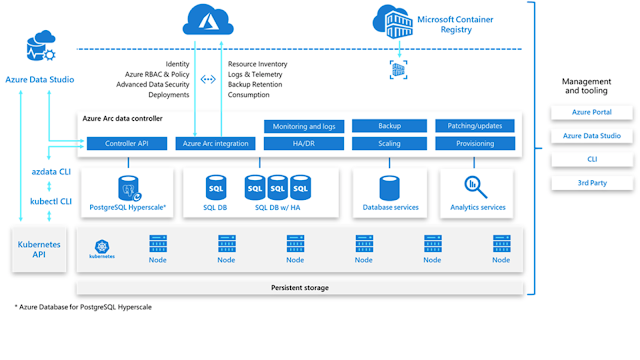
Diagram of full suite management capabilities provided by Azure Arc
Enterprise-gradeHybrid Hyper-Scale Microsoft Cloud OS Open.
Unmatched security
Security is a top priority for corporate IT. Yet it has been challenging to keep up the security posture and maintain consistent governance on data workloads across different customer teams, functions, and infrastructure environments. With Azure Arc, for the first time, customers can access Azure’s unique security capabilities from the Azure Security Center for their on-premises data workloads. They can protect databases with features like advanced threat protection and vulnerability assessment, in the same way as they do in Azure.
Azure Arc also extends governance controls from Azure so that customers can use capabilities such as Azure Policy and Azure role-based access control across hybrid infrastructure. This consistency and well-defined boundaries at scale can bring peace of mind to IT regardless of where the data is.
Learn more about the unique benefits with Azure Arc for data workloads.
Ready to break the limits?
Hyperscale enables you to develop highly scalable, analytical applications, and low latency experiences using your existing skills on both Azure SQL Database and Azure Database for PostgreSQL. With Hyperscale on Azure databases, your applications will be able to go beyond the traditional limits of the database and unleash high performance scaling.
- Learn more about Hyperscale on Azure Database for PostgreSQL
- Learn more about Azure SQL Database Hyperscale
- Learn more about Azure SQL Database serverless
What is Azure Synapse Analytics (formerly SQL DW)?
Explore the Azure Synapse (workspaces preview) documentation.
Azure Synapse is an analytics service that brings together enterprise data warehousing and Big Data analytics. It gives you the freedom to query data on your terms, using either serverless on-demand or provisioned resources—at scale. Azure Synapse brings these two worlds together with a unified experience to ingest, prepare, manage, and serve data for immediate BI and machine learning needs.
Azure Synapse has four components:
- Synapse SQL: Complete T-SQL based analytics – Generally Available
- SQL pool (pay per DWU provisioned)
- SQL on-demand (pay per TB processed) (preview)
- Spark: Deeply integrated Apache Spark (preview)
- Synapse Pipelines: Hybrid data integration (preview)
- Studio: Unified user experience. (preview)
Synapse SQL pool in Azure Synapse
Synapse SQL pool refers to the enterprise data warehousing features that are generally available in Azure Synapse.
SQL pool represents a collection of analytic resources that are being provisioned when using Synapse SQL. The size of SQL pool is determined by Data Warehousing Units (DWU).
Import big data with simple PolyBase T-SQL queries, and then use the power of MPP to run high-performance analytics. As you integrate and analyze, Synapse SQL pool will become the single version of truth your business can count on for faster and more robust insights.
Key component of a big data solution
Data warehousing is a key component of a cloud-based, end-to-end big data solution.

In a cloud data solution, data is ingested into big data stores from a variety of sources. Once in a big data store, Hadoop, Spark, and machine learning algorithms prepare and train the data. When the data is ready for complex analysis, Synapse SQL pool uses PolyBase to query the big data stores. PolyBase uses standard T-SQL queries to bring the data into Synapse SQL pool tables.
Spark as a Service with Azure Databricks
Synapse SQL pool stores data in relational tables with columnar storage. This format significantly reduces the data storage costs, and improves query performance. Once data is stored, you can run analytics at massive scale. Compared to traditional database systems, analysis queries finish in seconds instead of minutes, or hours instead of days.
The analysis results can go to worldwide reporting databases or applications. Business analysts can then gain insights to make well-informed business decisions.
More Information:
https://azure.microsoft.com/en-us/services/synapse-analytics/#features
https://docs.microsoft.com/en-us/azure/azure-sql/database/service-tier-hyperscale-frequently-asked-questions-faq
https://azure.microsoft.com/en-us/blog/get-high-performance-scaling-for-your-azure-database-workloads-with-hyperscale/
https://azure.microsoft.com/en-ca/blog/simply-unmatched-truly-limitless-announcing-azure-synapse-analytics/
https://docs.microsoft.com/en-us/azure/azure-sql/database/serverless-tier-overview
https://azure.microsoft.com/en-us/blog/bring-azure-data-services-to-your-infrastructure-with-azure-arc/
https://azure.microsoft.com/en-us/services/azure-arc/hybrid-data-services/#features
https://docs.microsoft.com/en-us/azure/azure-sql/database/service-tier-hyperscale